前言
这是pytorch深度学习的第三篇,第一篇为pytorch搭建CNN网络实现MNIST数据集的图像分类 ,第二篇为pytorch搭建AlexNet并训练花分类数据集,本篇将继续深入深度学习,介绍深度学习领域的经典神经网络——VGGNet,并利用pytorch自己动手搭建一个VGG-16网络来训练一个花分类的数据集。同时,本篇文章所有的代码都已上传github,欢迎大家star和fork。链接在此:begin-deep-learning
VGG简介
VGG 在2014年由牛津大学著名研究组 VGG(Visual Geometry Group)提出,斩获该年 ImageNet 竞赛中 Localization Task(定位任务)第一名和 Classification Task(分类任务)第二名。该模型的主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有常见的两种结构,分别是VGG16和VGG19,两者除了网络深度不一样,其本质并没有什么区别。其中VGG16包含了13个卷积层和3个全连层;VGG19包含了16个卷积层和3个全连层。
同时,VGG网络的一个创新点是通过堆叠多个小卷积核来替代大尺度卷积核,可以减少训练参数,同时能保证相同的感受野。例如,两个3x3步长为1的卷积核的叠加,其感受野相当与一个5x5的卷积核。但是采用堆积的小卷积核是优于大卷积核的,因为层数的增加,增加了网络的非线性,从而能让网络来学习更复杂的模型。并且小卷积核的参数更少,例如,假设使用3x3的卷积核,那么堆叠3次3x3的卷积网络的参数是\(3\times3^2C^2=27C^2\),而使用一个7x7的卷积核的参数是\(7^2C^2=49C^2\),这里的C是输入和输出的通道数。
VGG网络的优缺点
优点:
- VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- 几个小卷积核(3x3)的组合比一个大卷积核(5x5或7x7)效果好:
- 验证了通过不断加深网络结构可以提升性能。
缺点:
- VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用。其中绝大多数的参数都是来自于第一个全连接层。
感受野
感受野是机器视觉领域的深度神经网络中的一个概念,用来表示网络内部的不同位置的神经元对原图像的感受范围的大小。神经元之所以无法对原始图像的所有信息进行感知,是因为在这些网络结构中普遍使用卷积层和pooling层,在层与层之间均为局部相连(通过sliding filter)。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着他可能蕴含更为全局、语义层次更高的特征;而值越小则表示其所包含的特征越趋向于局部和细节。因此感受野的值可以大致用来判断每一层的抽象层次。通俗一点说就是,输出feature map上的一个单元对应输入层上的区域大小。
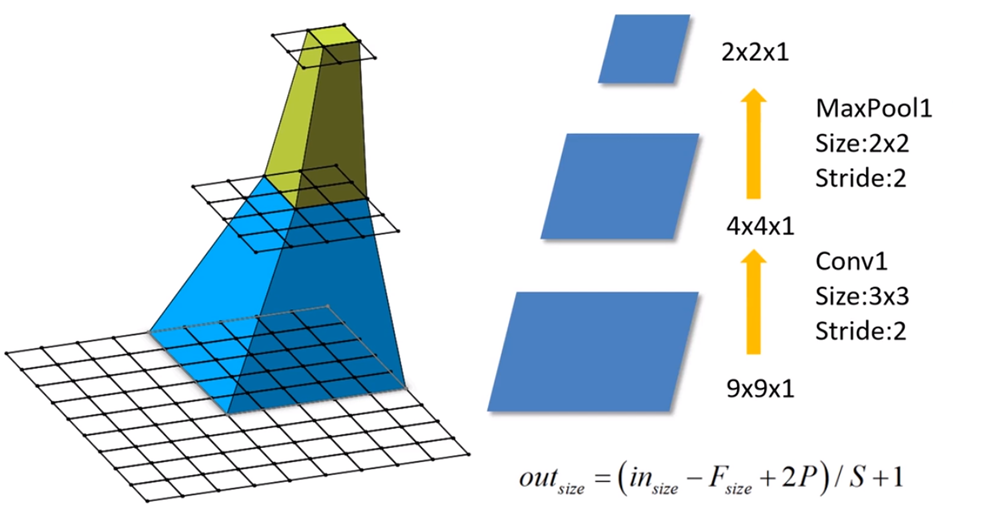
比如在上图中,输出层 layer3 中一个单元对应输入层 layer2 上区域大小为2×2(池化操作),对应输入层 layer1 上大小为5×5。
感受野的计算公式为:\[F(i)=(F(i+1)−1)×Stride +Ksize\]
- \(F(i)\)为第\(i\)层感受野
- \(Stride\)为第\(i\)层的步距
- \(Ksize\)为卷积核或池化核尺寸(即kernel_size)
比如,在上图中:
- Feature map: \(F(3)=1\)
- Pool1:\(F(2)=(1−1)×2+2=2\)
- Conv1: \(F(1)=(2−1)×2+3=5\)
所以,在VGG网络中,可以通过堆叠三个\(3\times3\)的小卷积核来代替一个\(7\times7\)的大卷积核,从而让结构更加清楚,并减少参数数量。
VGG网络结构
VGG网络有多个版本,各个版本的网络结构大致相同,一般常用的是VGG-16模型,即下图中的D。VGG的网络结构如下图所示:
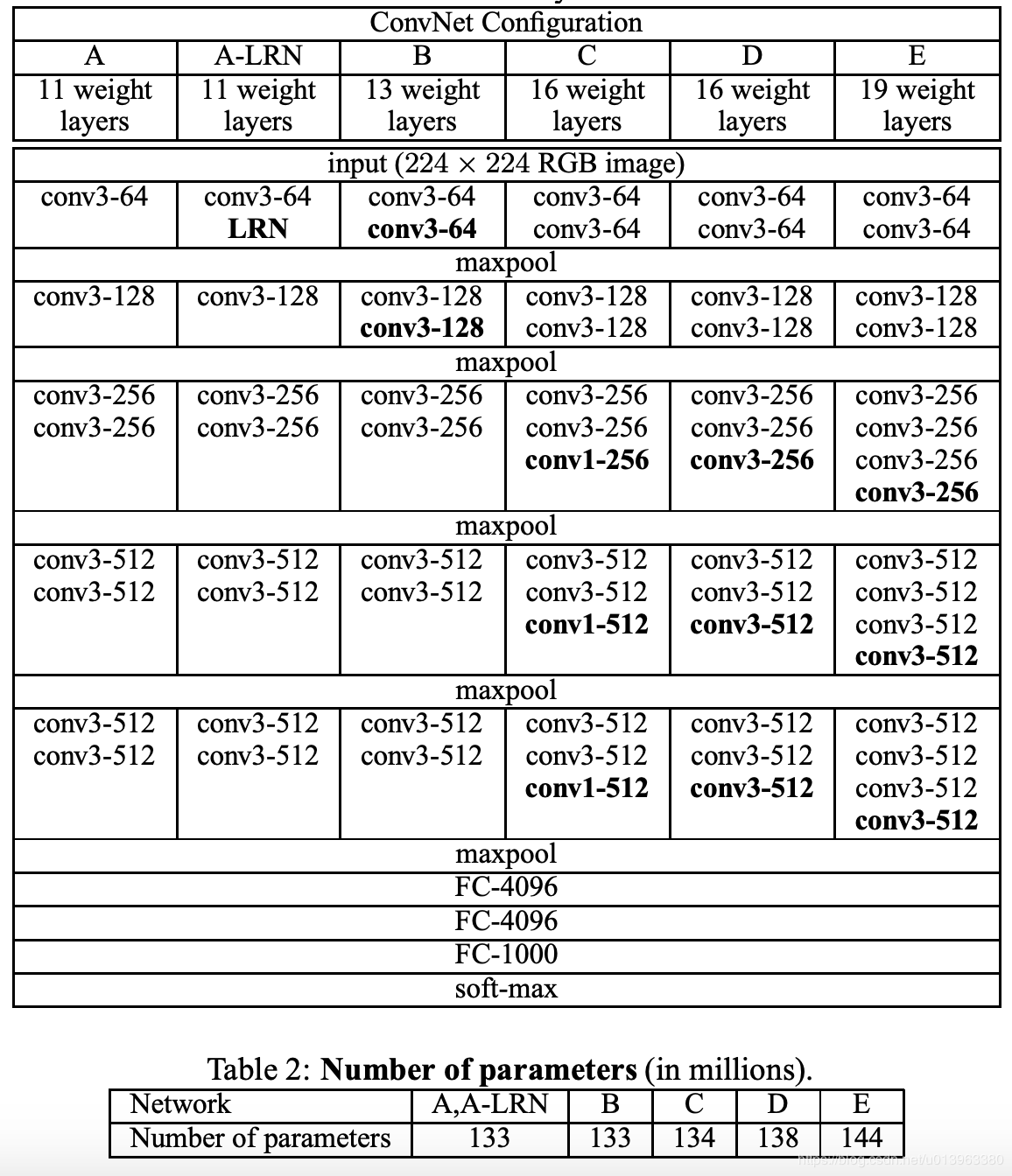
从图中可以看出来,VGG网络十分的整齐与美观,都是在一定数量的卷积层后加最大池化层,最终接入全连接层,卷积核大小均为\(3\times3\),同时,经过计算可以发现,经过\(3\times3\)卷积的特征矩阵的尺寸是不改变的:\(n^{[l]}=\frac{n^{[l-1]}+2p-f}{s}+1=\frac{n^{l-1}-3+2}{1}+1=n^{l-1}\) .
代码实例分析
数据集
数据集仍采用上次训练AlexNet的数据集,具体数据集的下载以及划分请参看上一篇pytorch搭建AlexNet并训练花分类数据集。
具体代码
因为一般常用的是VGG-16模型,所以这里就以VGG-16模型来编写代码,即上图中的D部分。
module.py
与上次AlexNet模型的代码结构差不多,也是分为卷积层和全连接层,按照上边的架构图一步步写出来就好了,看着上面的结构表来写模型真的没什么难度...下面是具体代码,有什么不懂的可以看注释。
1 | import torch |
train.py&&predict.py
这部分代码跟上一个模型属实差别不大,就基本照抄,注意把模型名字换了就行,这里就不再赘述了。有需要的可以到我的GitHub去看,train.py,predict.py
结果展示
训练过程

这里解释一下只显示10个epoch的原因是我之前训过30个epoch,但是最高准确率只达到0.797,所以我又多训了10个epoch,看看有没有什么提升,结果升到了0.813,所以我就把我训到的最好的结果放出来了,但是可以明显看出,VGG网络的分类准确率是比AlexNet更高的,已经达到了80%,提高了将近10个百分点,还是比较明显的提升。
预测过程
同样的,使用的是跟上一次AlexNet一样的预测脚本和预测图片,下面是结果:

AlexNet的预测结果:

通过与AlexNet的预测结果的对比可以看出VGG网络的预测准确率确实比AlexNet要好,只不过参数更多,训练起来更麻烦,更耗时。
总结与提升
写完自己的VGG-16以后,又去拜读了pytorch官方对于VGGNet的实现,一下子确实感受到了差距,我自己实现的VGG-16就只是按照模型按部就班一步一步写出来,而pytorch官方则将VGG网络的多种网络结构(VGG-11,VGG-13...)统一成一个模型,代码也简洁的多,我当时自己实现的时候还觉得把每一步都写出来好像有点憨,读了pytorch的源码之后才发现确实有更好的写法,所以看来以后还是要提升写代码的水平,多读一些大佬的代码,提升业务水平才重要。有兴趣的可以亲自去看一看pytorch关于vgg实现的源码,这里给一个链接。vgg.py